{kind=link}
Disclaimer: The methods described in this article are for learning purposes only and should not be used against production systems you do not own. Since publication TRA has updated their software and the methods described here pose no risk to their systems.
One of the most frustrating things about the design of the Taiwan Railways Administration (TRA) online booking system is the lack of transparency into whether or not seats are actually available on a train before attempting to book. A customer is required to fill out an entire page of booking details and complete a CAPTCHA only to be shown an "Order Ticket Fail:No seat available in this journey" message.
With no other options to query seat availability, the obvious solution is to automate these booking requests until seats are found. CAPTCHAs are typically designed to protect resources from non-human requests like this, but some CAPTCHAs are designed better than others, and with a bit of scripting it turns out the TRA booking system can be fooled relatively easily.
This project demonstrates a method for doing just that using Python and some basic image processing. The code is available on GitHub.
Cleaning the captcha
There are two main pieces to breaking the catpcha: isolating characters from the original image, and then guessing what each character is by comparing image data to a sample training set.
To give you an example of what we're dealing with, here are a few examples of captchas I've encountered:
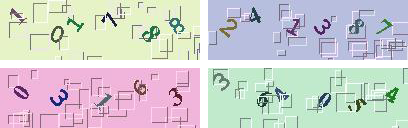
As you can see they're not the greatest captchas in the world. There's some color variation, a bit of background noise, rotation in the characters, but the real weakness is only numerical digits are used and all captchas only have either 5 or 6 characters. This means we'll only have to guess among 10 possibilities instead of 30+ you'd expect in a normal alphanumeric captcha. We also know exactly how many characters to expect, which significantly increases the accuracy of our decoder.
The first step is to remove anything that isn't part of a character, so we'll try and get rid of the background color and those weird web-1.0-looking boxes. We can take advantage of the fact both the background and boxes are generally lighter than the characters and filter out colors above a certain pixel value.
colors = sorted(
filter(
lambda x: x[1] < max and x[1] > min,
im.getcolors()
),
key=itemgetter(0),
reverse=True
)[:n]
Here we're returning the n most prominent colors in the image by pixel color frequency, ignoring pixels above (lighter than) max or below (darker than) min. All the images we're working with here have been converted to 256 color pallete gifs, so 255 always represents white. Next we'll use this list of colors to build a new monochrome image using only pixels from the original that appear in our list of prominent colors.
sample = Image.new('1', im.size, 1)
width, height = im.size
for col in range(width):
for row in range(height):
pixel = im.getpixel((col, row))
if pixel in colors:
sample.putpixel((col, row), 0)
If we run this against the top right captcha in the image above the result looks like this:
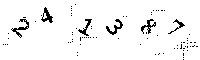
This is already looking pretty reasonable, but some of the background noise still remains and will cause trouble when we try and break the image into characters. This can be removed by doing some more filtering:
im = im.filter(ImageFilter.RankFilter(n, m))
The rank filter takes windows of n pixels, orders them by value, and sets the center point as the mth value in that list. In this case, I'm using n=3 and m=2, but these numbers were just eyeballed and there's probably a better way to do this. Here's what the filtered image looks like:
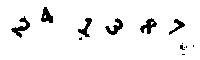
Now it's looking pretty obvious where the characters are. Things are a little blurrier from the filter but luckily this doesn't matter as the character shapes are still unique enough for comparison. The last step is to break them up into features.
arr = numpy.asarray(im.convert('L'))
labels, _ = ndimage.label(numpy.invert(arr))
slices = ndimage.find_objects(labels)
features = []
for slice in slices:
feature = arr[slice]
features.append((feature, numpy.count_nonzero(feature),
slice[1].start))
Here we're taking advantage of scipy's ndimage to determine slices representing contiguous areas of black pixels in our image, pull those features out of the image, and create a list of features along with their pixel count and starting x-coordinate. Since we know there are only 5 or 6 characters in the captcha we only need to look at the 6 largest features.
features = sorted(
filter(lambda x: x[1] > min_pixels, features),
key=itemgetter(1),
reverse=True
)[:max_features]
features = sorted(features, key=itemgetter(2))
Features with pixel counts below min_pixels are filtered out, we only return max_features features (6 in this case), and the features are sorted from left to right. This list, when converted back to images, looks how we'd expect:

Now it's time to take a guess at what these characters are.
Using the vector space model to compare images
Some research (googling) led me to Ben Boyter's Decoding Captchas book where he uses a vector space model for classifying images and calculating similarity values. It works, the math isn't too complicated, and it sounds cool to talk about things in vector space. That's good enough for me.
The vector space model is something that appears frequently in text search. Documents can be represented as vectors where components are weights of specific terms, and it's then possible to retrieve relevant documents by comparing a query to a list of documents by examining the angle between their respective vectors.
We can do the same thing for images, except instead of words we're going to be identifying images by pixel values. Let's take these three blown-up images for example:
A
|
B
|
C
|
It's obvious to a human A and C are more similar visually. Now we need to teach our future AI overlords.
We can convert each of these images into vectors by setting each component to a pixel value, either 0 for white or 1 for black, left to right, top to bottom. Doing this yields:
$$
\bf{A} = [0, 1, 1, 1, 0, 0, 0, 1, 0]\\
\bf{B} = [0, 0, 1, 0, 1, 1, 1, 1, 0]\\
\bf{C} = [1, 1, 1, 1, 0, 0, 0, 1, 0]\\
$$
Now that we have vector space representations of our images, we need to compare them somehow. It turns out the cosine of the angle between two vectors is relatively easy to calculate:
$$
\cos\theta=\frac{\bf{A}\cdot\bf{B}}{\vert\vert\bf{A}\vert\vert\:\vert\vert\bf{B}\vert\vert}
$$
Remember both the norm of a vector and the dot product of two vectors return scalars, which is what we expect since we're looking for a cosine. Identical images will have no angle between them so \(\theta=0\) and \(\cos\theta=1\), and since we're only dealing with postive values, completely unrelated images will be orthogonal, i.e. \(\theta=\pi/2\) and \(\cos\theta=0\). Let's do the math for A and B:
$$
\bf{A}\cdot\bf{B}=\sum_{i=1}^n\it{A_iB_i}=2\\
\vert\vert\bf{A}\vert\vert\:\vert\vert\bf{B}\vert\vert=\sqrt{\sum_{i=1}^n\it{A}_i^2}\sqrt{\sum_{i=1}^n\it{B}_i^2}=\sqrt{20}\\
\cos\theta=\frac{2}{\sqrt{20}}\approx0.4472
$$
Not so close. However, if we do the same for A and C:
$$
\cos\theta=\frac{4}{\sqrt{20}}\approx0.8944
$$
That's a much better match. Python makes it easy to do this for PIL images:
def cosine_similarity(im1, im2):
def _vectorize(im):
return list(im.getdata())
def _dot_product(v1, v2):
return sum([c1*c2 for c1, c2 in izip(v1, v2)])
def _magnitude(v):
return sqrt(sum(count**2 for c in v))
v1, v2 = [vectorize(im) for im in scale(im1, im2)]
return _dot_product(v1, v2) / (_magnitude(v1) * _magnitude(v2))
Making some training data
Armed with a way of isolating characters from the original captcha and a method for comparing image similarity we can start cracking captchas.
The one tricky thing about these captchas is the characters have a random rotation angle. And while we could try to deskew the characters or rotate them and compare to a sample iconset, I thought it would probably be easier just to generate an iconset containing samples already rotated at various angles.
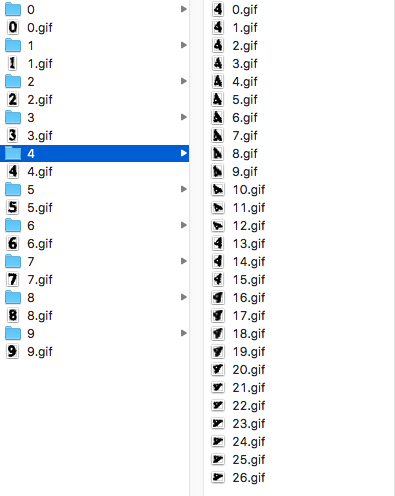
Putting it all together
It's a bit brute force, but now all our decoder has to do is compare each isolated character to the sample iconest and pick the character with the greatest similarity:
def guess_character(self, im, min_similarity=0.7, max_guesses=5):
guesses = []
for symbol, icon in _get_icons():
guess = cosine_similarity(im, icon)
if guess >= min_similarity:
guesses.append((symbol, guess))
return sorted(
guesses,
reverse=True,
key=itemgetter(1)
)[:max_guesses]
Next steps
My initial goal for the project was 20% accuracy and I was pleasantly surprised that just eyeballing parameters for the image processing yielded a whopping 40% accuracy over my test dataset. Note to developers: that's what happens when you try and roll your own captcha. The biggest trip-ups seem to be overlapping characters and leftover noise artifacts from filtering.
Overlapping characters could be dealt with by considering a maximum pixel size for features. We already have a minimum feature pixel size to filter out leftover background noise, so why not add a maximum pixel feature size, split chunks larger than that horizontally, and hope they're not too weird for the guessing bits? Because I'm lazy, that's why.
Filter settings could probably be optimized further to deal with leftover background noise, but at the end of the day I'm calling 40% squarely in "ain't broke" territory.
Thanks for reading.